Document Intelligence Training Service
Overview
The Document Intelligence Training Service empowers business users to configure how Document Intelligence understands and processes their specific document types. Through an intuitive interface, users can define standardized schemas, configure document mappings, and validate extraction accuracy - all without requiring technical expertise.
The Training Service puts document automation control in the hands of business users - the people who understand your documents best. This ensures accurate data extraction while eliminating technical barriers.
Key Components & Concepts
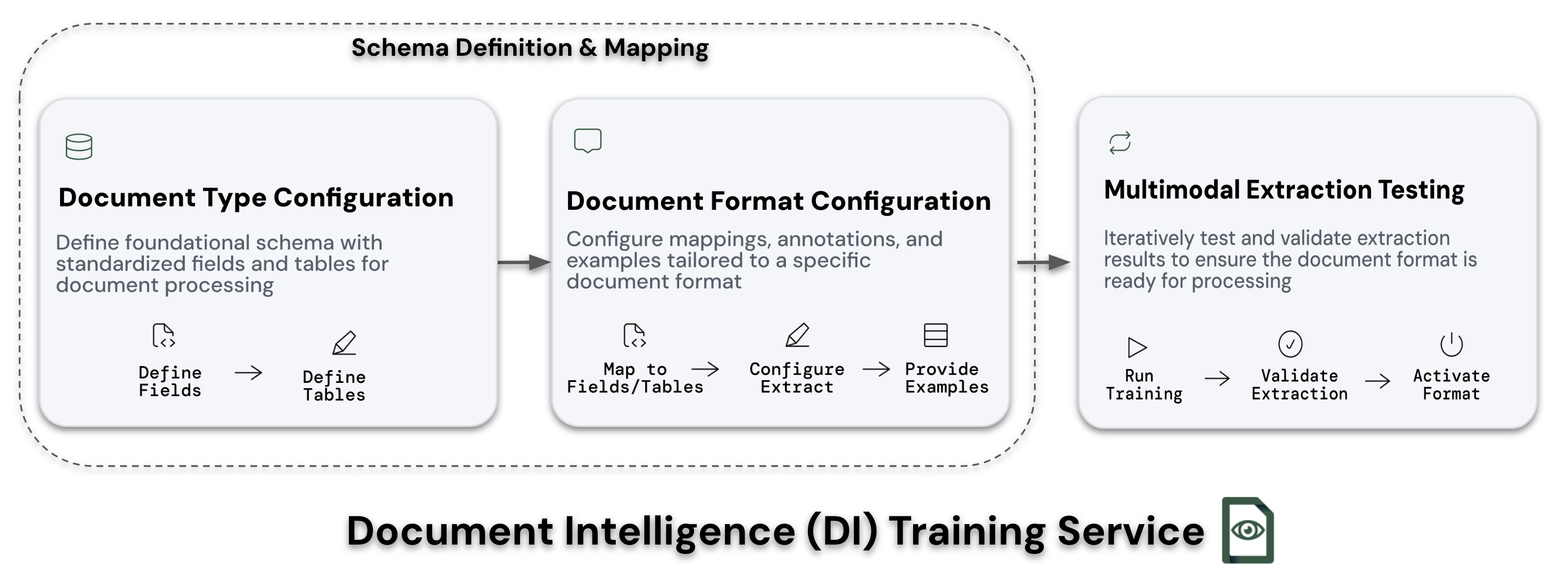
Processing Flow
Document Type Configuration
The foundation of document processing begins with Document Type configuration:
- Define standardized fields and requirements
- Configure table structures
- Set validation rules
- Enable agent-based validation
Document Types create a consistent processing framework, ensuring all documents of the same category are handled uniformly regardless of their source format.
Document Format Configuration
For each variation of your Document Type:
- Map source fields to standard schema
- Configure visual annotations
- Provide few-shot examples
- Set format-specific rules
Start with your most common document format to establish baseline mappings, then create additional formats for variations.
Extraction Training
Validate and activate each Document Format:
- Test with sample documents
- Verify extraction accuracy
- Validate business rules
- Activate for production
Always thoroughly test extraction accuracy across a representative sample of documents before activating a format for production use.