Get to know your data
The first step is to know the data structures you work with. This has two aspects: the data structures your clients send you and the related data structures in your internal systems for invoicing.
Firstly, let's have a look at the files your clients send you. It's important to understand the data structures you'll be feeding to Document Intelligence to process.
Here's an analogy: A teacher (you) needs to know very well the matter they're teaching their students (Document Intelligence), right? That's exactly the case here. You're about to teach Document Intelligence how to parse the documents. That means you need to know them.
First look at the document
Here's an example remittance document:
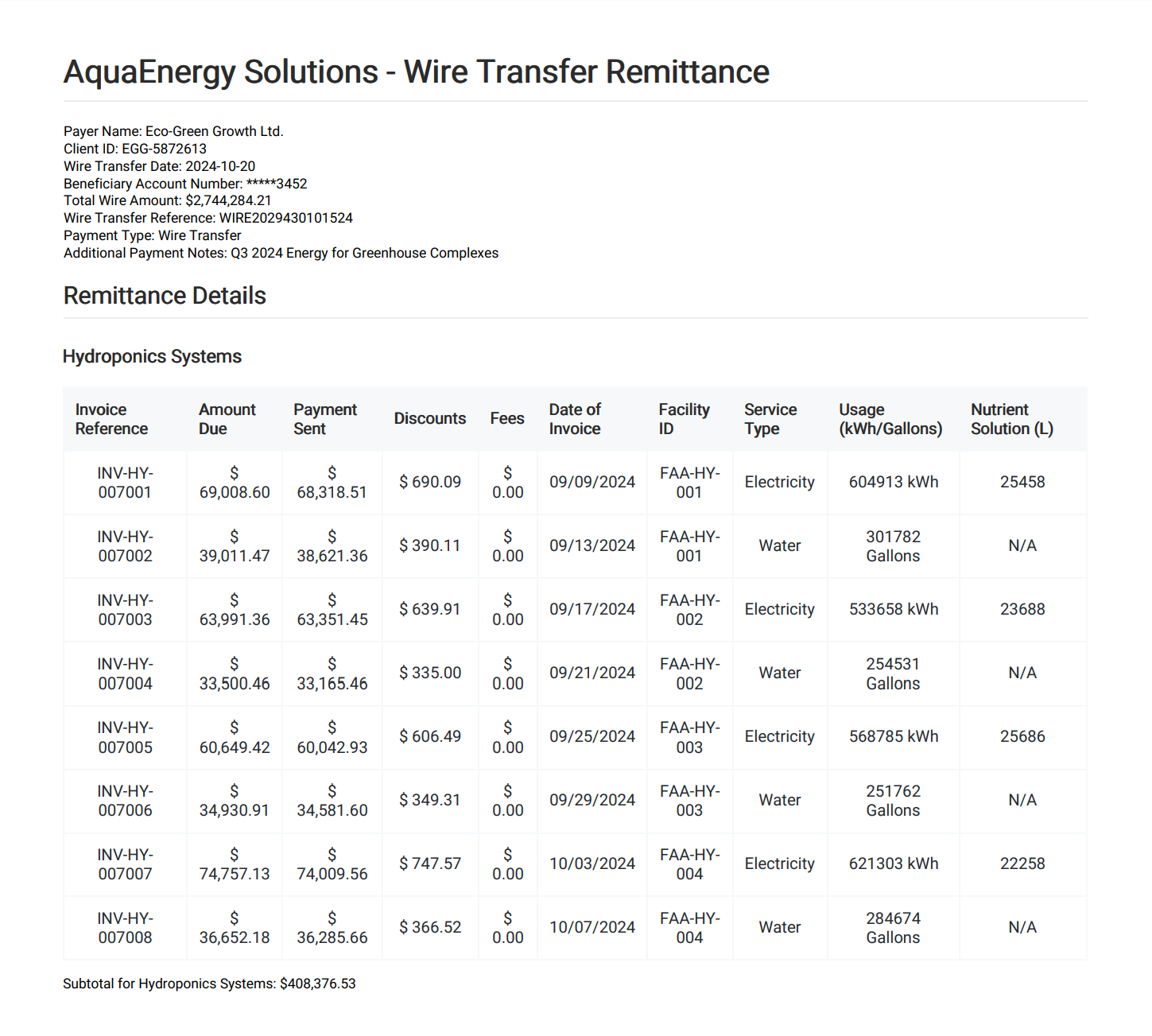
There are three important sections of the document:
- The semi-structured fields at the top that contain the payer name, total payment amount, payment date, etc.
- The table and its heading designating which sub-entity of the client is the table related to (here: Greenhouse Complexes). There may be as many such tables in one document as there are sub-entities the payment is consolidated for.
- The sub-total for each sub-entity beneath the table. This value must match the sum of the payments in the corresponding table.
Review the document carefully to identify key fields and table cells and map them to your internal systems. Start with one payment type and a client mapped to a single structure. Test the workflow thoroughly before adding more payment types and clients.
A terminology reminder:
- For one whole remittance reconciliation use case, you'll define one document type because that's the content model for your data.
- For each payment type and client combination, you'll define one document format because these pairs likely use different document structures.
Output of this activity
Print your remittance document, take a color marker, and highlight the data you need to extract. Then, take a pen and write what you call the data in your systems for each data label.
You can, of course, do this digitally and in whatever way it is comfortable to you. The point is to have a clear idea of what data you need to extract and how the data labels from your clients map to what you use. Here's an inspiration:

Terminology: fields vs. tables
Before diving into document type creation in the next unit, let's take a moment to solidify terminology groundwork and avoid confusion later on.
There are typically two types of data structures in text documents like PDFs:
- Tables: Consist of cells made by rows and columns with headers (see the green rectangle in the picture above).
- Fields: Lines of text usually structured as key:value pairs, such as Payer name: HygroGro Systems (see the red and blue rectangles in the picture above).