Define the document format
Document format is a variation of a document type, mapping actual document data labels to the document type structure. Once you create your document type, you need to teach Document Intelligence how to map the data in your documents to the content model in the document type.
Create a document format
- In Work Room, go to Documents using the left-side navigation menu.
- Click Configure on the card of the type to which you want to add formats.
Before you proceed, we suggest you once again go through the document type and make sure you didn't leave out any columns or tables. Once you create the document format, adjusting it to fit changes in the document type increases the chances of data extraction errors.
Select a document format representative
You may have many document formats for one document type. Pick a representative file for a chosen group of remittance documents and set up a document format for this group. You'll repeat the same set of actions for every document format you may have.
- Select the Formats tab.
- Click Format > Create Now.
- Type the name of the document format under Document Format Name. For example, Wire Transfer.
- Click Add Files and select a PDF remittance document on your computer.
- Confirm in the preview you uploaded the right file and click Next.
Teach Document Intelligence where how to find your data
When you defined document type, you specified what kind of data you expect to work with. Now is the time to map that structure to the actual file.
- Click the colored dot on the right under Table Headers & Sample Rows.
- Read the description hinting at what data you should select. This is the description you wrote in the document type.
- Draw a same-colored rectangle around the appropriate data segment in the PDF.
- Make sure to follow the instructions in the right sidebar.
- To adjust the selection, draw it again—that'll remove the previous one. You can retry as many times as you need.
- Click Done once you finish annotating the document.
- Click Next .
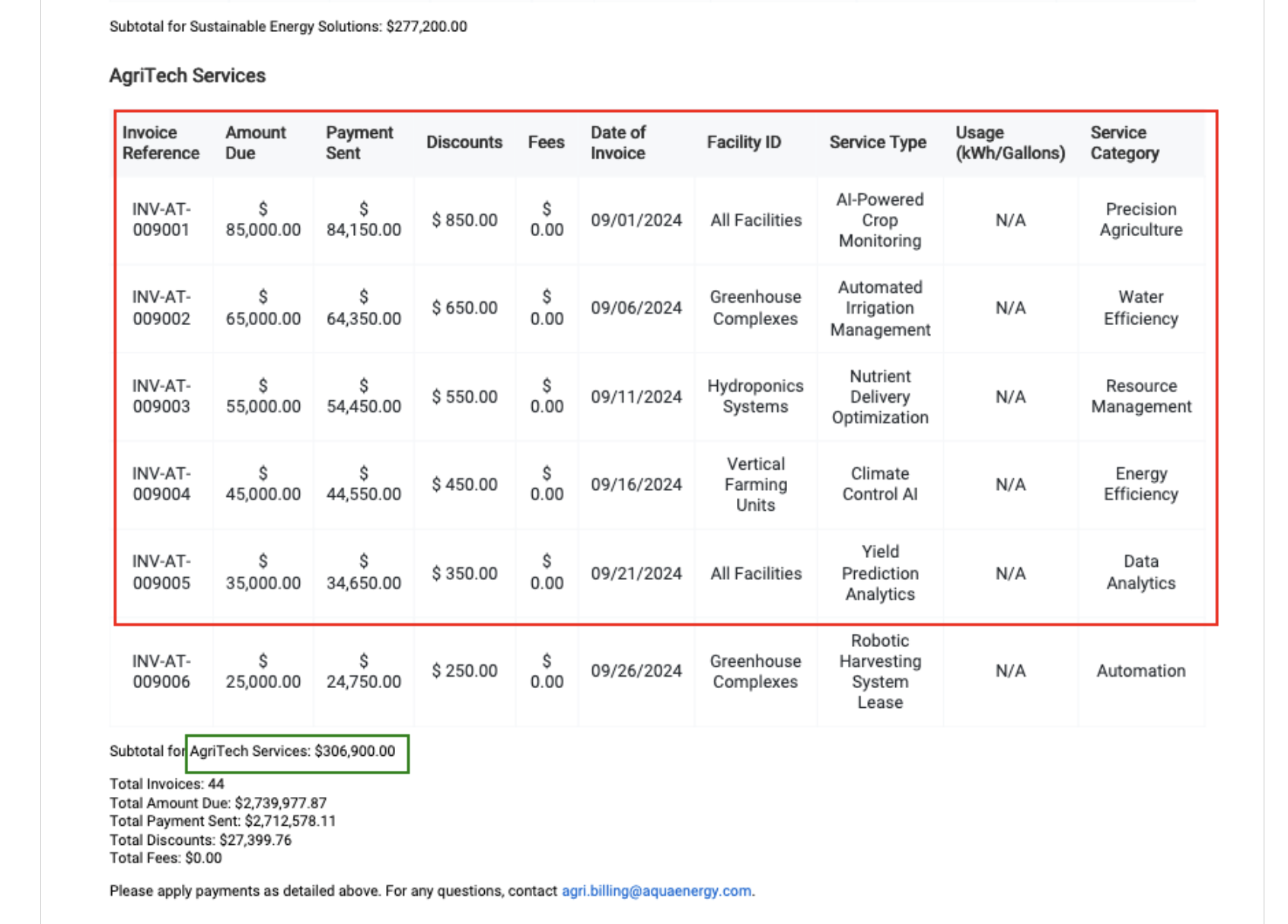
If you defined multiple tables in the document type as we did earlier (Invoice Details and Facility Type Subtotal), you'd draw multiple rectangles of different colors. For the invoice details, draw a red rectangle around all the columns and 5 of the rows. For the second derived table, called Facility Subtotals, draw a blue rectangle around the table footer with the facility name and the subtotal. See examples. If multiple tables of the same type exist across multiple pages, annotate at least of 2 of them by going to the next page.
Map the data labels
After you define the location of the table, Document Intelligence looks at the PDF and does its best to map the columns you defined in the document type to the columns it finds in the PDF.
For example, Document Intelligence thinks, “You defined Invoice Number, I see Invoice Reference. I think that's the same column.” And so it binds those two fields together.
The columns it fails to recognize, you need to map manually. Even if Document Intelligence maps everything, be sure to always check the mapping because it may not get the mapping right. The right Mapped To column needs to contain column names as they're in the PDF you uploaded.
You need to complete this mapping for both fields and tables.
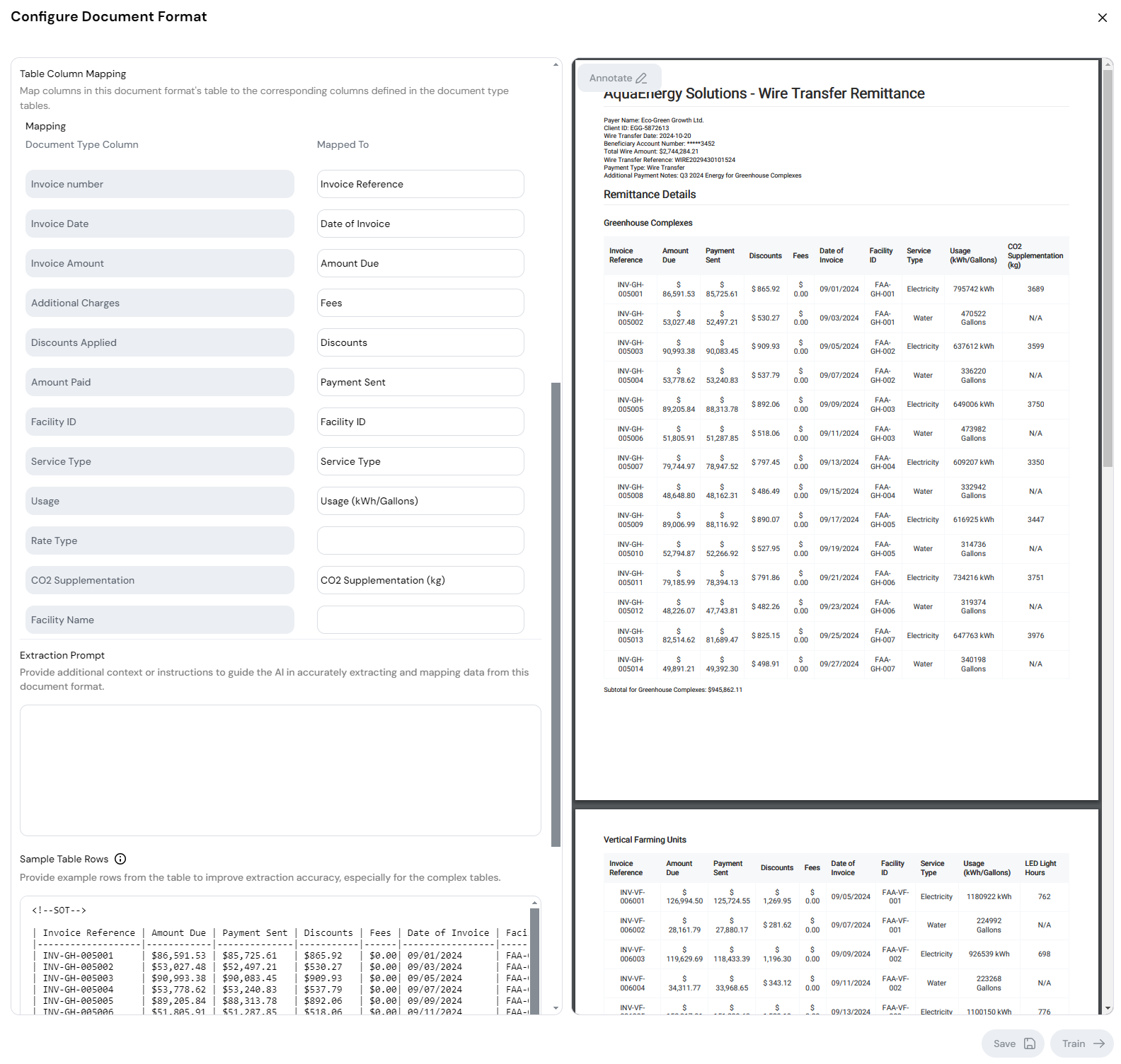
Mappings for Facility Name and Subtotal Invoice Amount are derived using the subtotal information at the footer of every table. We will configure this extraction via the prompt in the next section. Hence, leave the mappings blank.
Guide AI to more accurate extraction
Under the column mapping rows, you see Extraction Prompt text area.
Extraction prompts guide the Document Intelligence in identifying and extracting data fields across different document layouts. This is particularly useful for filling in the derived column Facility Name, for instance, or the whole second table with subtotals, because there's no unique data label to identify the data by.
In this example, we'll use an extraction prompt for both tables to improve the chances of correct data extraction:
Extract two sets of tables from the document using the following rules:
### For **Table 1 (Invoice Details):**
* This table captures detailed invoice-level information for customer payments made to Aqua Energy Solutions. It includes columns:
* `Invoice Reference`, `Amount Due`, `Payment Sent`, `Discounts`, `Fees`, `Date of Invoice`, `Facility ID`, `Facility Name`, `Service Type`, `Usage (kWh/Gallons)`, `CO2 Supplementation (kg)`.
* The column **Facility ID** may be labeled differently across tables. It can appear as **Unit ID**, **System ID**, or simply **Facility**. Treat all these labels as the same column, and extract the relevant ID for each row.
* **Facility Name** is a derived column that should be added to the extracted table. Populate this column with the Facility Name name based on each section’s subheader (e.g., "Greenhouse Complexes" or "Vertical Farming Units") and ensure every row in the section has the same Facility Name value.
* Ensure that all other data is extracted based on the columns specified, including `Service Type`, `Usage`, and `CO2 Supplementation`.
### For **Table 2 (Facility Subtotals):**
* This table captures summary information of total invoice amounts grouped by Facility Name. It includes:
* `Facility Name`, found in the section header, and `Subtotal Invoice Amount`, found in the bottom line of each table.
* For example, 'Subtotal for Greenhouse Complexes: $820,112.06' can be found at the bottom of each table. Extract "Greenhouse Complexes" as the Facility Name and `$820,112.06` as the `Subtotal Invoice Amount`.