Train Document Intelligence
Training Document Intelligence refines how the service extracts and processes your documents. This ensures accurate data extraction across various formats while maintaining data integrity and validation rules.
During training, you will:
- Test document extraction against mappings
- Validate extraction accuracy
- Review performance metrics
- Iterate configurations to achieve desired results
Before starting training, ensure you have:
- Completed document type configuration
- Set up at least one document format
- Prepared sample documents for testing
Training process
Once you have everything set up, click Train to submit the document format definition for training.
This takes you to the Training tab in the document type setup. Once training is complete, the State field changes from Extraction Stage to Completed.
Follow the steps below for detailed guide on Document Intelligence training.
Submit document for training
- From your document format configuration, click Train.
- Document Intelligence processes the document using:
- Field mappings
- Table definitions
- Extraction prompts
- Custom configurations
Monitor training progress
Work Room shows training status updates in real time:
- Extraction Stage: Document is processed.
- Processing: Mappings and transformations are applied.
- Completed: Training finished successfully.
- Failed: Training encountered errors.
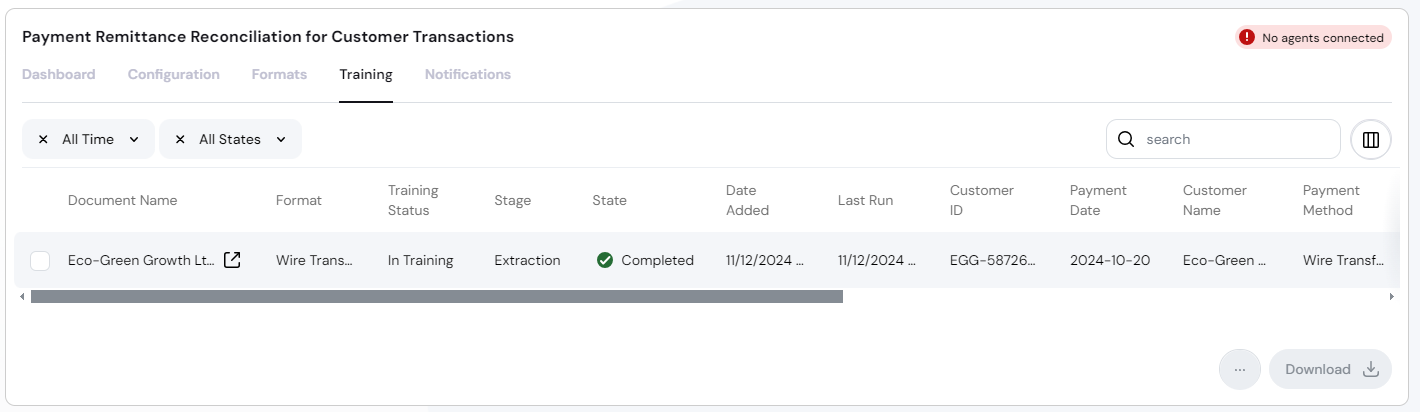
Review extraction results
Click icon right of the document name to open the training details.
You have two ways to review the training results:
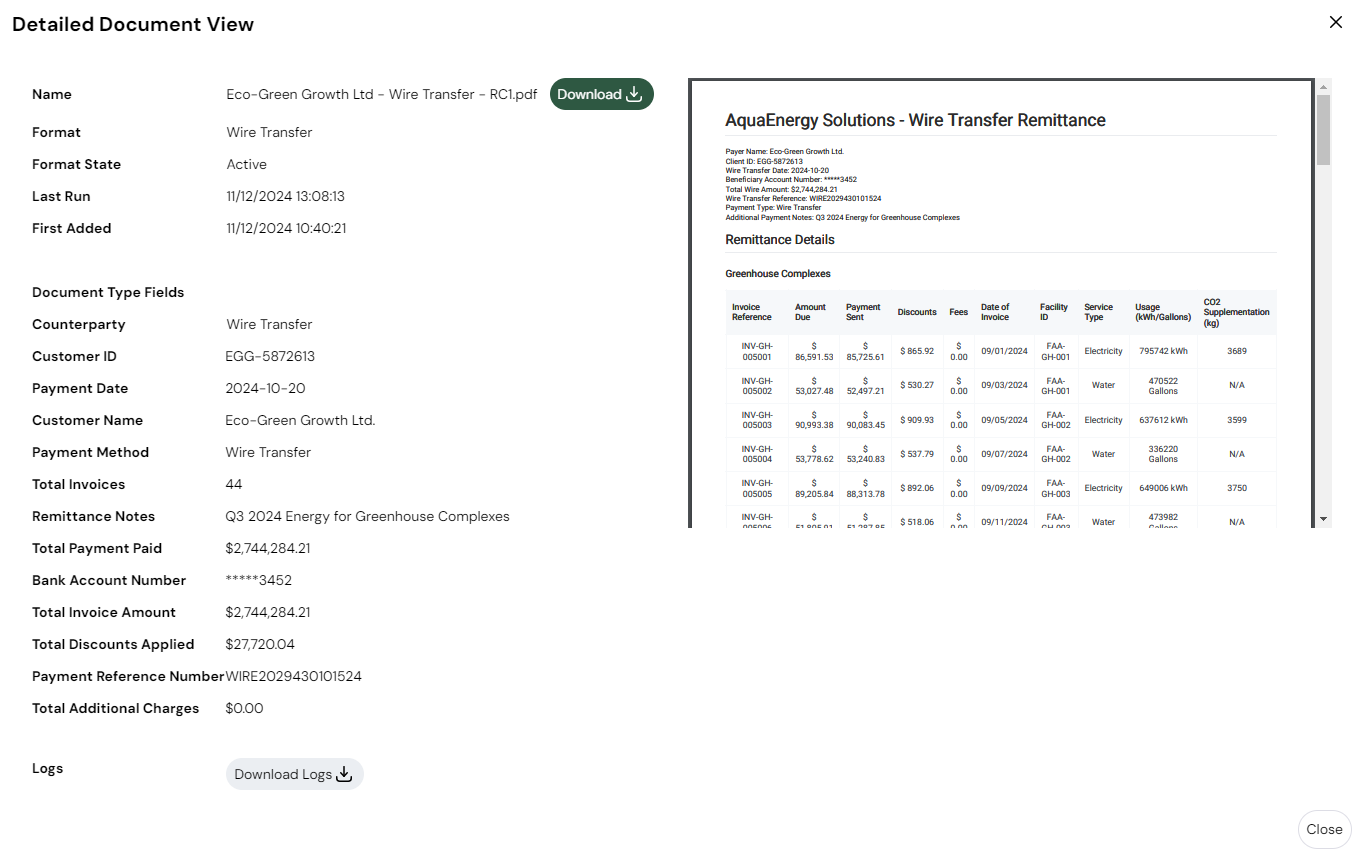
- Visual inspection:
- View extracted data in the preview pane.
- Verify field mappings.
- Confirm table structure.
- Detailed analysis:
- Click Download > Extract Content.
- Review JSON output for extraction details.
- Analyze metrics and quality indicators.
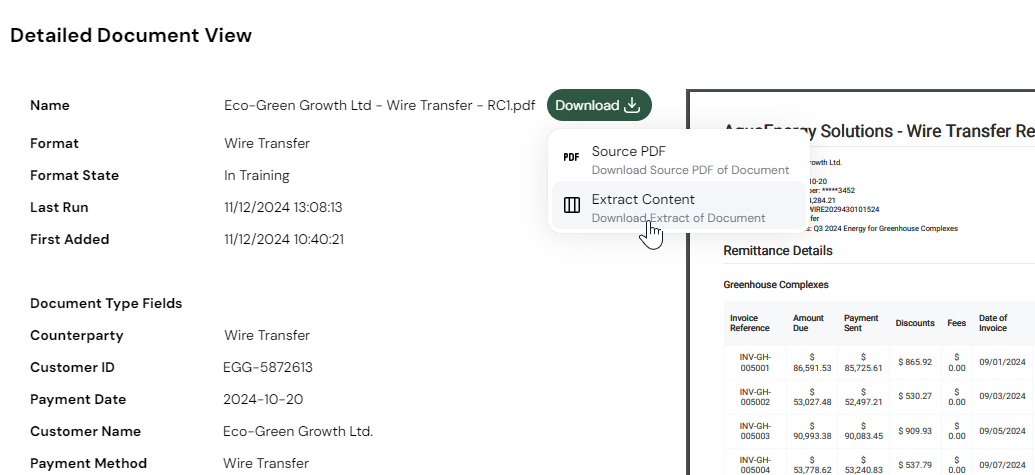
We recommend you reindent the JSON file for readability using a suitable text editor, such as Sublime Text with the Indent XML package. Even after reindentation, you'll need to convert \n to actual new lines to view the file contents somewhat comfortably.
Key metrics to review:
- Field extraction accuracy
- Table structure integrity
- Data validation status
- Processing performance
Analyze training metrics
Document Intelligence provides the following metrics to evaluate training quality:
Extraction metrics
- Total tables processed
- Rows successfully extracted
- Empty columns identified
- Column mapping accuracy
Data quality indicators
- Completeness (%)
- Consistency (%)
- Accuracy (%)
Performance metrics
- Processing time
- Resource utilization
- Pipeline efficiency
Iterate and improve
If results need improvement:
- Click and select Retrain.
- Adjust configurations:
- Refine field mappings
- Update extraction prompts
- Modify table definitions
- Repeat the training process.
Common reasons for retraining:
- Incorrect field mappings
- Missing table data
- Poor extraction quality
- Performance issues
Activate trained format
Once results meet requirements:
- Select the trained document using the checkbox.
- Click and select Approve.
- Format status updates to "Active".
This activates the document format. Any new documents that land in Document Intelligence in this format will be picked up for extraction by Document Intelligence multi-modal pipeline.
Training best practices
Document selection
- Use representative samples covering all variations.
- Include edge cases and special formats.
- Test with different document qualities.
- Validate across multiple pages.
Iteration strategy
- Start with basic configurations.
- Test with a small sample set.
- Analyze results thoroughly.
- Incrementally add complexity.
- Document configuration changes.
Performance optimization
- Monitor extraction times.
- Review resource usage.
- Optimize prompts for efficiency.
- Balance accuracy and speed.
Troubleshooting
Common issues
Failed extractions
- Review extraction logs.
- Verify document format.
- Check mapping configurations.
- Validate prompt syntax.
Poor quality results
- Analyze quality metrics.
- Review field mappings.
- Update extraction prompts.
- Test with different samples.
Performance problems
- Check document size.
- Review prompt complexity.
- Monitor system resources.
- Optimize configurations.
Getting help
Access detailed logs for troubleshooting:
- Click Download in the training interface.
- Select Download Logs.
- Review error messages and warnings.
Contact Sema4.ai support for additional assistance with:
- Complex extraction scenarios
- Performance optimization
- Custom configurations
- Integration issues