Document Intelligence Multimodal Extraction Service
Overview
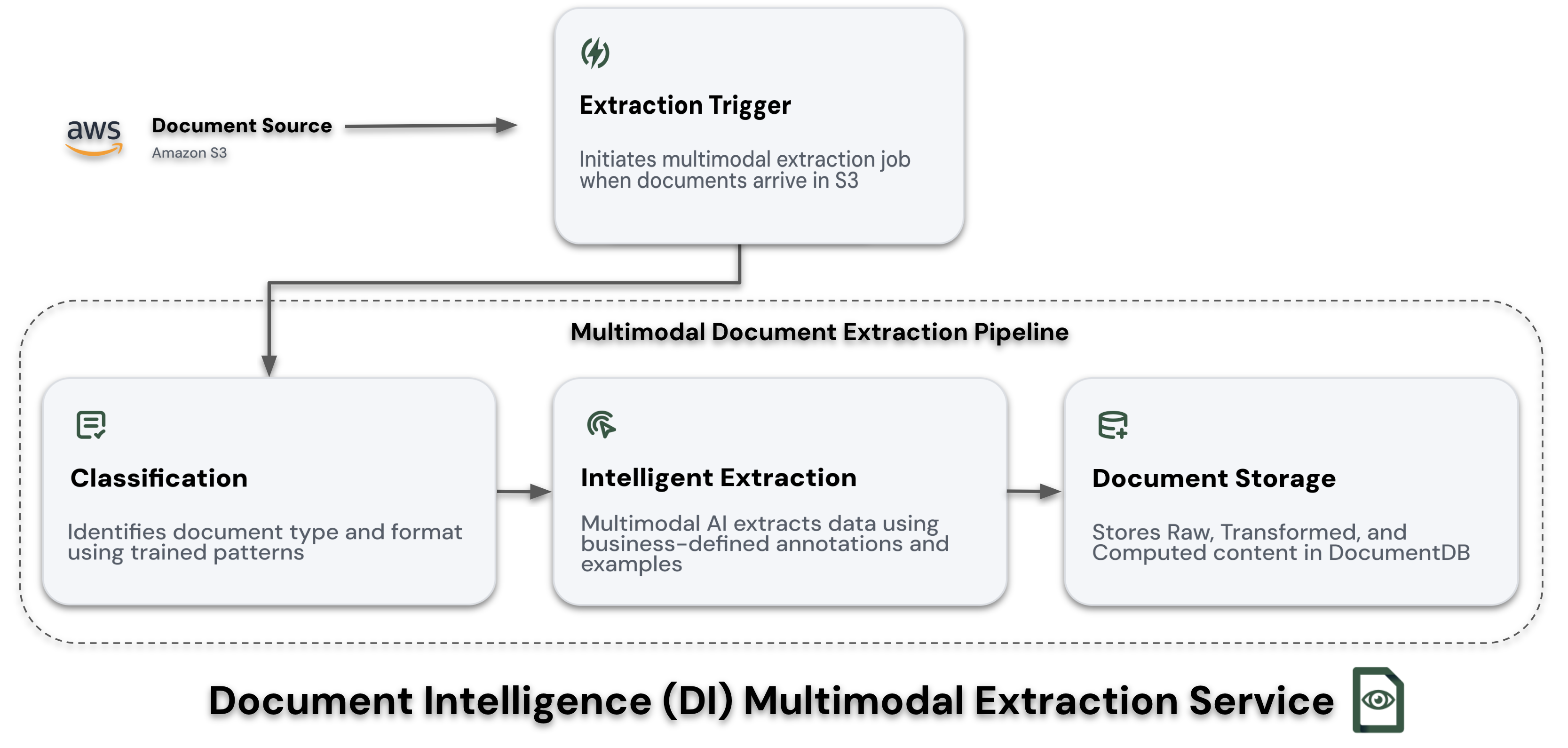
The Document Intelligence Multimodal Extraction Service transforms unstructured documents into accurate, validated data through an advanced AI-powered pipeline. This service combines sophisticated document classification, intelligent extraction, and structured storage to ensure reliable data processing at enterprise scale.
The Extraction Service leverages multi-modal AI capabilities along with business-defined configurations to ensure accurate and consistent extraction across all your document types, preparing data for autonomous processing by Worker Agents.
Key Components & Concepts
Processing Flow
1. Document Arrival & Classification
When a document arrives in S3:
- Trigger detects new document
- Extracts classification from path
- Initializes extraction context
- Prepares document for processing
Classification through S3 path structure ensures reliable document routing while maintaining clear organization of your document processing workflows.
2. Intelligent Extraction
The extraction engine applies multiple layers of intelligence:
- Base field and table mappings
- Custom extraction prompts
- Visual annotation rules
- Multi-shot examples
Visual annotations combined with multi-shot examples significantly improve extraction accuracy for complex document layouts.
3. Validation & Storage
Final processing stages:
- Validates extracted content
- Transforms to standard format
- Stores in DocumentDB
- Creates work item trigger
Always ensure extraction configurations are thoroughly tested across a representative sample of documents before deployment.