

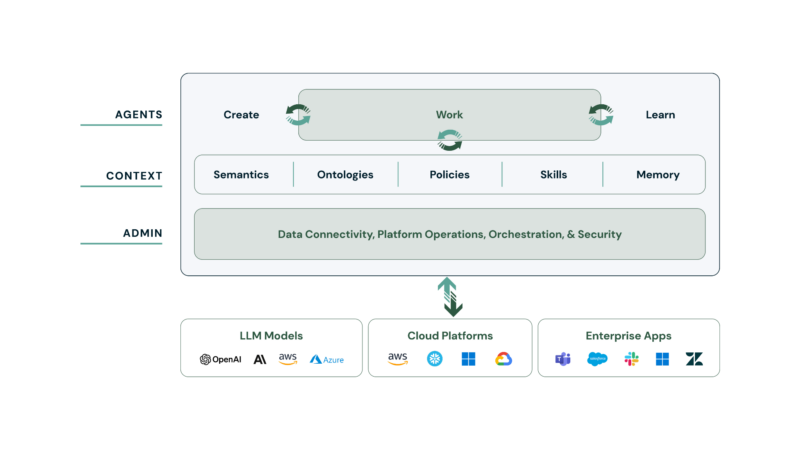
If you’re building enterprise AI agents for complex back-office work, you know the gaps between “impressive demo” and “production-ready system.” Your team has the use cases. Your operations need the capacity and efficiency promised from AI. But getting agents into production for document-heavy, multi-step workflows has required too much engineering effort, too little business context, and too many compromises on accuracy and governance. That’s the gap an enterprise AI agent platform needs to close, and why we’ve designed this release to focus on production readiness across every layer.
Less than 25% of enterprise AI experiments ever reach production, and more complex use cases drive success rates even lower. The reasons are consistent: generic tools lack the robust document intelligence, cross-system semantic and business understanding, support for adaptive governance, and deterministic execution for accuracy that teams demand. Developers build promising prototypes that stall at the compliance wall or collapse under real-world process variability and the control needed at enterprise scale.Today’s platform release changes that equation across every layer. We’ve reimagined how agents are built, deepened how they understand your business, and simplified how they deploy at enterprise scale. Here’s what’s new and why it matters for your organization.
Build agents in hours, not weeks
The biggest barrier to enterprise AI adoption isn’t technology. It’s access. The people who understand your processes best (your finance analysts, transformation leaders, and operations managers) have been locked out of building and refining agents because the tools required developer skills. They carry the tribal knowledge, every edge case, every vendor quirk, every exception that makes a process actually work. But translating that expertise into technical specifications has meant filing IT tickets and waiting weeks.
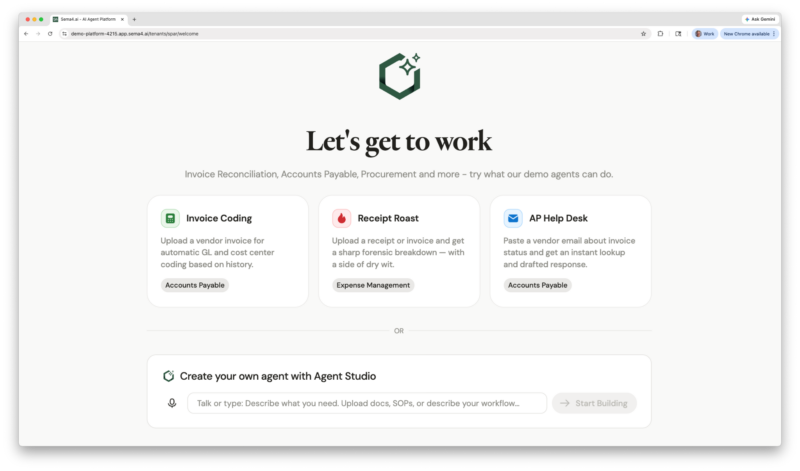
Guided by AI, reimagined agent building becomes a simplified and easily iterative process. Business users work in plain English, either through speaking or typing, with interactive Q&A steps to define the agent’s Runbook. For more advanced instructions, they can upload existing SOPs or specific related documents. Users describe exception rules, set tolerance thresholds, and explain vendor-specific handling directly, no code, no flow diagrams, no IT tickets.
Over time, the platform also actively recommends improvements: clearer instructions, more efficient skill usage, and optimizations based on execution patterns. Every suggestion is grounded in how the agent actually performs, not generic best practices. Teams that previously waited days for developer availability are now empowered to build, refine and tune agents quickly, and the agents they build are better because the people with the deepest domain expertise are shaping them directly.
Pre-built skills eliminate the need to teach agents fundamental operations from scratch. Extract data, Reconcile, Classify, Detect Exceptions, Notify, etc.: these composable, domain-specific operations come ready to use, simplifying how agents are built and run. Runbooks focus solely on your unique details while leveraging underlying, shareable skills.
Custom skills capture institutional expertise and share it organization-wide. When your team develops a specialized operation (say, a particular vendor’s non-standard invoice format or a region-specific tax calculation), they package it as a reusable skill without writing code. That expertise becomes available to every agent across the organization, ensuring consistency and eliminating duplication. Agents combine multiple skills for end-to-end processes (extraction, validation, reconciliation, and action) without custom integration code.
Agents that get smarter with use
Enterprise AI that starts from zero on every interaction isn’t enterprise-ready. Your team has spent years building institutional knowledge about how your processes actually work: which vendors send inconsistent formats, which data sources lag behind others, which exceptions require escalation versus auto-resolution. That knowledge shouldn’t evaporate between sessions. Your agents now remember, learn, and improve autonomously.
Agent memory retains corrections, user preferences, and exceptions across conversations. When an analyst corrects how a vendor’s invoice should be handled or flags a data format variation, that knowledge persists permanently. The same correction never happens twice. Every adjustment the team makes teaches the system, and the system applies those lessons automatically on every future run.
Autonomous journaling captures successes, failures, and data quirks into a persistent, compounding knowledge base. The platform doesn’t just remember what you tell it; it actively observes what works and what doesn’t. Document format variations, edge cases, timing dependencies, and exception-handling rules are recorded automatically without requiring the team to document them explicitly. The 500th document processed costs a fraction of the first because the agent has learned from every preceding transaction.
AI-driven recommendations surface proactively, transforming passive learning into active improvement. The platform suggests new Runbook rules based on patterns it has observed, proposes skills that could be created from repeated code patterns, and flags areas where agent performance could be strengthened. It’s not just intelligence that accumulates; it’s intelligence that acts on itself, getting faster, more accurate, and less expensive over time without manual intervention.
Deep business context, automatically
Enterprise AI agents need more than data access, they need to understand business relationships, rules, and context the way your team does.
Generic AI tools see database tables. They know column names and data types. But they don’t understand that “vndr_id” in your ERP and “supplier_code” in your AP system are the same entity. They don’t reason about the business relationships that make reconciliation, matching, and validation possible. Your agents now see your business the way your team does.
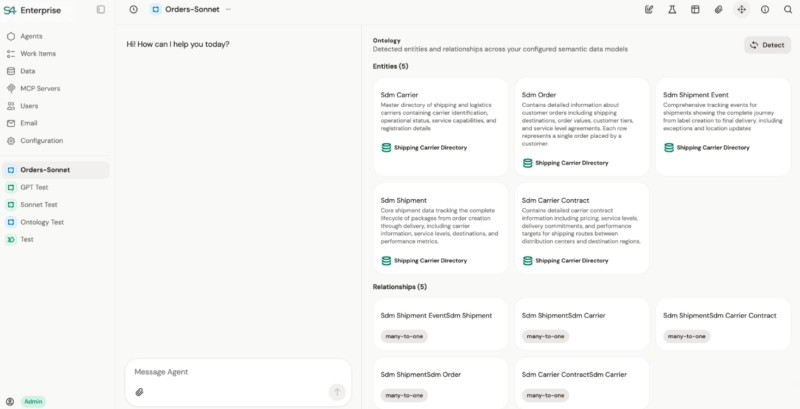
Business ontologies define core entities (customers, orders, invoices, shipments), their relationships, and operational rules. Agents reason about business concepts rather than columns and rows. When processing a reconciliation, an agent understands that an invoice references a purchase order, which connects to a goods receipt, which ties to a vendor master record, even when these live in completely different systems with different naming conventions and different identifiers.
Automatic ontology detection eliminates weeks of manual data modeling. Point the platform at your data sources and AI infers entity relationships from column names, data types, sample values, and foreign key patterns. It detects duplicate entities across systems and proposes merges with confidence scoring. Review the proposed business ontology, refine it, and save. Your agents immediately gain cross-system business intelligence that would have taken a data architecture team weeks to configure manually.
Business rule validation and governance let business users define controls in plain English: “reject duplicate payments to the same vendor within 30 days” or “credit limit increases above $50K require 12 months of customer history.” Agents enforce these rules before taking any action. If the AI cannot evaluate a rule, the operation is denied and escalated, not skipped. This fail-closed design ensures governance is never bypassed, even in edge cases the system hasn’t encountered before. Your compliance team gets the controls they’ve been asking for without creating bottlenecks.
Semantic layer enhancements round out the business context capabilities. Source-level data filtering ensures only relevant rows are materialized, dramatically improving performance across complex multi-source queries. Business users can browse and connect data sources without engineering support, making the entire data landscape accessible through conversation rather than SQL.
One question, and your AI agent answers from every system
Enterprise data lives everywhere. A single reconciliation might need invoice records from Snowflake, payment confirmations from Postgres, vendor details from a master data CSV, and rate tables from a spreadsheet. Today, getting answers that span these sources requires an engineering project. Your agents can now query across all of it in a single operation.
Federated queries span Snowflake, Postgres, CSV files, and spreadsheets simultaneously. The platform automatically decomposes cross-source questions into dialect-correct subqueries for each backend, pushes filters to source databases before transfer (so you’re retrieving 100 relevant rows, not downloading 10 million to filter locally), and joins only the results that matter. No engineering project required. Business users ask questions in plain English that would have previously required a data analyst, a SQL developer, and a week of lead time.
Verified queries lock approved SQL for frequently asked questions, eliminating LLM generation delays, variability and costs. Everyone gets the same accurate answer, every time, with no redundant processing and no risk of the model generating slightly different (and potentially incorrect) SQL on different runs. For finance operations where consistency matters, this is the difference between a tool you can trust and one you have to verify.
Verified logic takes determinism further: agents execute real, traceable Python, and the platform observes when repeated patterns emerge. Those patterns are automatically promoted to versioned, tested modules that execute deterministically. Same input, same output, every run. Compliance teams verify a module once rather than evaluating probabilistic output on every transaction. The economics improve with volume as more processing shifts from generated code (expensive, variable) to compiled modules (fast, consistent, auditable).
Simpler architecture, faster deployment
Getting to production shouldn’t require a six-month infrastructure project. Organizations have told us that deployment complexity, security, and governance at scale are the reasons AI experiments stall between pilot and production. This release fundamentally simplifies the path from “we built an agent” to “we have agents running in production.”
Fully web-based means no desktop installations and no compatibility issues across team members running different operating systems or software versions. Teams start building within minutes of getting access, and every platform improvement is available the moment it ships, no upgrade cycles, no migration projects, no IT coordination to get everyone on the same version.
Enhanced governance flexibility is provided with granular control over who can access, build, and share agents. Role-based permissions ensure users only see what they’re authorized to use. Agents follow a draft/live lifecycle: builders iterate privately, share with specific reviewers as Editors or Viewers, and publish when ready. Skills are shareable organization-wide, capturing expertise once for reuse across agents. Shared action gallery management controls which integrations are available per workspace. Business users move fast while IT retains full visibility over what’s deployed and who can access it.
Multi-cloud availability simplifies deploying on AWS, GCP, Azure, or Snowflake.dYou have your choice of infrastructure with the same experience between providers. Agents run entirely within your VPC with zero-copy data access: no data leaves your security boundary, no replication creates new risks, and you maintain complete control over where processing occurs and where data resides. Your cloud choice is a deployment preference, not a capability constraint.
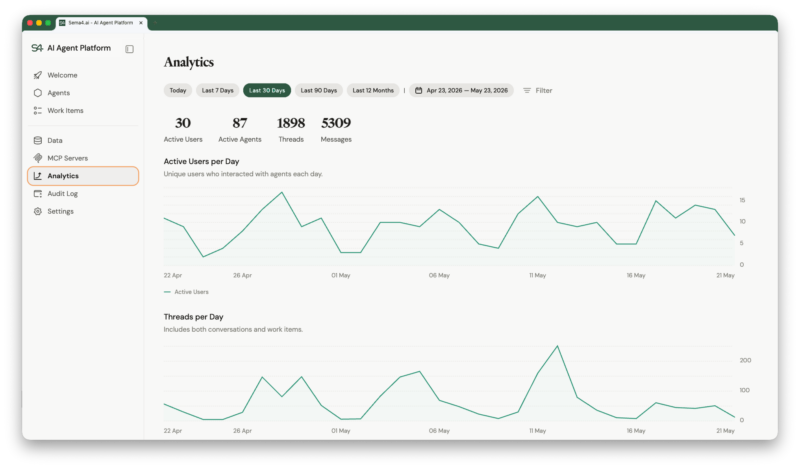
Enhanced platform insights track conversations, work items, and active users per agent with time-series charts and configurable date ranges. Per-user breakdowns reveal adoption patterns and help you identify which agents are driving value and which need attention. Every agent decision is logged with SOX-ready evidence, complete before-and-after differentiations, and three-lens visibility that serves analysts (plain-language summaries), auditors (compliance certificates), and engineers (raw execution traces) with purpose-built views.
Data connectivity is simplified via our MCP Access Gallery that provides 40+ pre-built connectors to enterprise tools (Slack, HubSpot, Jira, Asana, Box, GitHub, Google Workspace, and more) with guided setup. For internal tools or vendors not in the gallery, configure custom MCP servers that fully support any HTTP-based endpoint. Connect once at the workspace level and attach to any agent. What used to take a developer half a day now takes an admin two minutes.
What this means for your team
This release reflects a simple thesis: the people who understand the work should own how agents do the work. The platform should provide the intelligence, context, and governance to make that possible at enterprise scale without requiring those people to become developers.
Whether you’re a transformation leader encoding your team’s expertise into agents, a finance operations director seeking straight-through processing rates above 80%, a CIO looking to consolidate 15 shadow AI tools under one governed platform, or a platform engineer evaluating enterprise-grade AI architecture, this release delivers meaningful progress toward those goals.
The gap between AI experimentation and AI production is not inevitable. It is an architecture problem. And architecture problems have architecture solutions.