


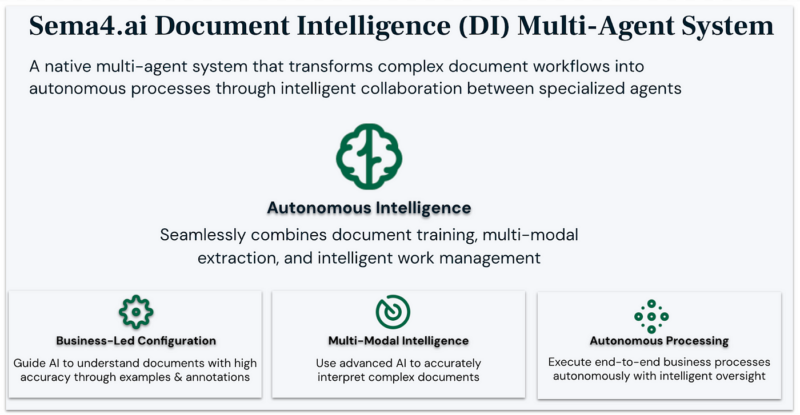
Sema4.ai Document Intelligence multi-agent system
Since launching Document Intelligence (DI) as part of the Sema4.ai Enterprise Agent Platform at the end of last year, we’ve seen tremendous interest from enterprises looking to transform their document-centric workflows. From hours to seconds. From manual effort to autonomous processing. From simple document retrieval to end-to-end business automation — this is the transformation our customers have experienced.
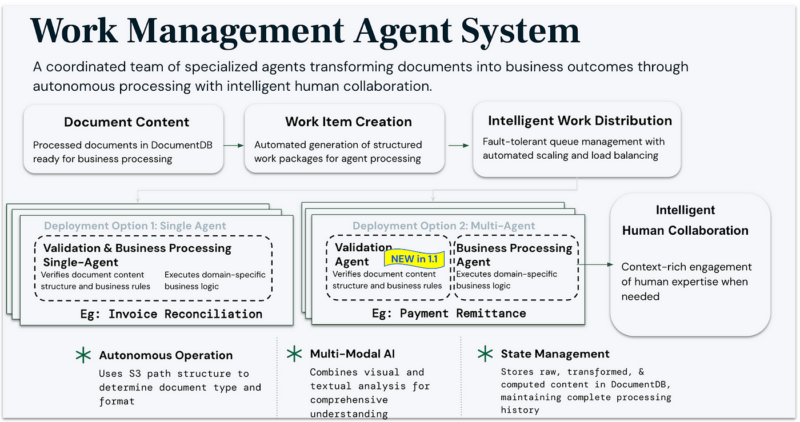
Our initial launch and December webinar showcased how our Work Management Agent System revolutionizes business processing through autonomous operation with intelligent human collaboration.
However, a deeper question kept emerging from enterprises: How can their business analysts handle the complex data engineering traditionally required for document automation — the intricate transformations, hierarchical relationships, and unified views that typically require specialized technical skills?
Traditional approaches like RAG have focused on making document content more accessible, but they don’t address the fundamental challenge of transforming unstructured documents into actionable business data. Enterprises need something radically different — a solution that not only empowers business analysts to perform sophisticated data engineering through natural language but also provides autonomous agents to execute these transformations at scale. Today, we’re excited to pull back the curtain on our complete multi-agent architecture and introduce powerful new capabilities in DI with the Sema4.ai Enterprise Agent Platform 1.1 release that makes this vision a reality.
Through natural language instructions and intuitive visual tools, business analysts can now:
- Engineer sophisticated data transformations without writing code
- Model complex document structures through visual annotations rather than technical configurations
- Maintain data hierarchies and relationships using natural language instead of ETL pipelines
- Continuously refine processing through business feedback rather than code changes
Check out the video below and experience firsthand how our Document Understanding Agent transforms complex document automation through intuitive visual interaction — enabling business analysts to configure sophisticated document processing in minutes rather than weeks.
The Power of specialized agent teams
Traditional document AI focuses on better extraction or simpler RAG-based retrieval. Sema4.ai DI represents a fundamental advancement through its native multi-agent architecture. Each specialized agent masters a critical phase of the document lifecycle:
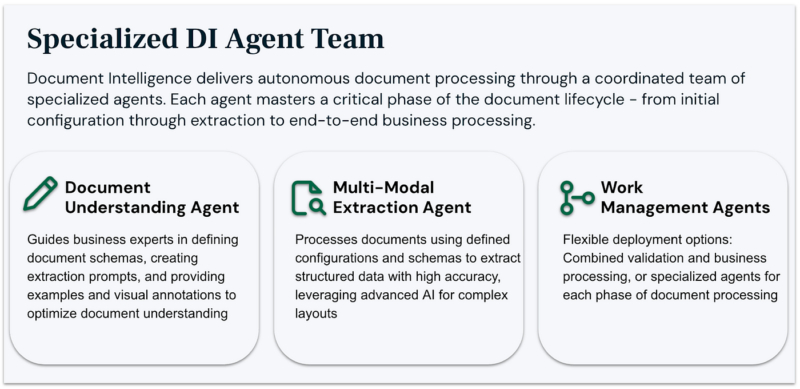
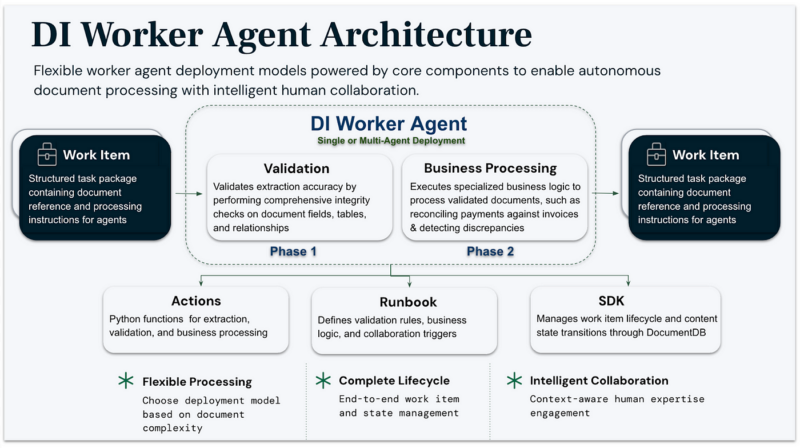
Document Understanding Agent (DUA)
At the foundation of our architecture sits the Document Understanding Agent (DUA), which guides business experts in defining document schemas and optimization rules.
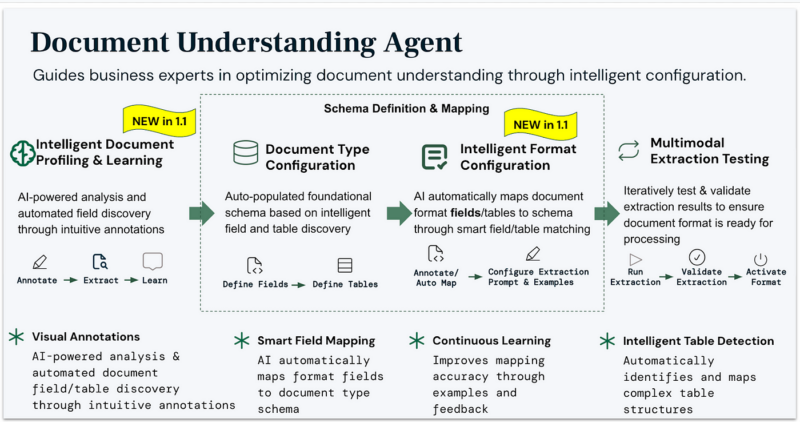
The Document Understanding Agent: Bridging the gap between business expertise and technical implementation through intuitive visual tools and natural language configuration
With DI 1.1, this agent gains powerful new capabilities:
- AI-powered schema generation from unstructured documents
- Intuitive visual annotation interface
- Automated format creation and validation
- Continuous learning from user feedback
We will go through the details of these capabilities in subsequent sections.
Multi-modal extraction agent
Our extraction agent represents a fundamental advancement over traditional OCR and template-based approaches. The system creates a comprehensive semantic model of each document by combining visual layout analysis with natural language understanding. This enables accurate extraction even from complex layouts with:
The agent automatically:
- Dynamic table structure recognition
- Contextual field relationship mapping
- Automatic handling of document variation
- Preservation of business logic and hierarchies
Operating automatically when new documents arrive, this agent leverages advanced AI to transform unstructured documents into accurate, validated data. Unlike simple OCR or template-based approaches, the agent combines visual and textual analysis for comprehensive understanding, ensuring high-quality extraction across complex layouts, through a sophisticated pipeline:
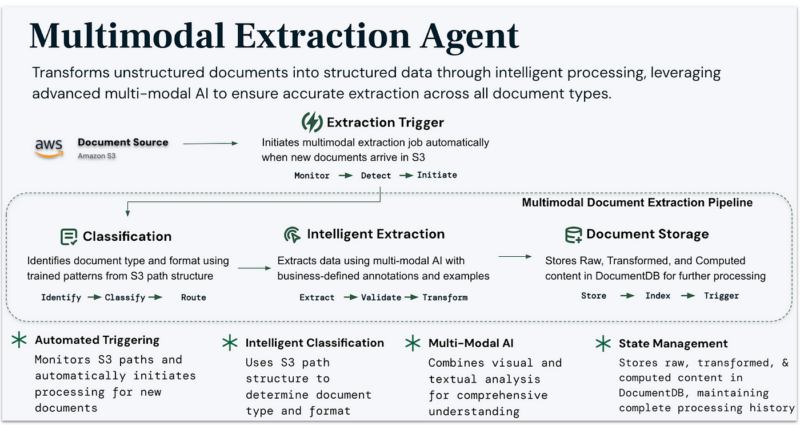
The agent automatically:
- Monitors document sources and triggers processing
- Classifies documents using trained patterns
- Extracts data using business-defined rules
- Validates and transforms content for downstream use
Work management agents
These agents handle the crucial final phase — turning extracted data into business outcomes. With flexible deployment options (single agent or multi-agent), they manage everything from validation to domain-specific processing, knowing exactly when to engage human expertise.
AI-generated document schema: transforming complex unstructured documents into actionable data
Understanding document complexity: a real-world example
Let’s explore how the Document Understanding Agent (DUA) transforms complex document processing through the example of a 100-page utility remittance document. This document type presents significant challenges:
- Spans over 100 pages
- Contains multiple facility types (Greenhouse Complexes, Vertical Farming Units, etc.)
- Includes repeated table structures across pages
- Features hierarchical relationships between line items and facility subtotals
- Requires cross-page data aggregation and summarization (via virtual columns and virtual tables that we’ll discuss in the next section)

This complexity is further amplified by the diverse variations in how enterprises receive these documents. A single document category, such as remittance documents, can arrive in numerous formats depending on the payment method, source system, etc. For example, wire transfers, ACH payments, and corporate consolidated payments all contain the same essential information but present it with different layouts, terminology, and structural organization.
This variation in document formats presents a significant challenge for traditional document automation approaches. A wire transfer remittance might list facility details in clearly structured tables, while an ACH payment document could embed the same information within a different arrangement of fields and sections. A corporate consolidated payment might combine multiple facilities into a single document with its own unique organization.
Traditionally, handling these document variations required specialized data engineering skills — writing code to normalize different formats, maintain relationships, and create unified views. The DUA transforms this paradigm by enabling business analysts to handle these complexities through natural language and intuitive visual tools.
To address this complexity, the Document Understanding Agent employs two fundamental concepts:
- Document Type — serves as a standardized schema that captures the essential structure and requirements shared across all remittance documents, regardless of their source. This includes core fields like Customer ID and Payment Amount, along with structured tables for invoice details and facility summaries.
- Document Format — adapts this standard schema to handle the specific ways different payment methods present this information, enabling accurate processing despite varying layouts and terminology.
For the example below, we will create a document type called “Payment Remittance” and a document format called “Wire Transfer,” representing the payment method.
Intelligent document profiling & learning
Traditional document automation approaches would require extensive technical configuration, often taking days of specialized development work to handle these intricate relationships. Business analysts mus coordinate with technical teams to define schemas, create extraction rules, and implement complex data transformations. The DUA guides business analysts through a sophisticated yet intuitive process of document understanding that unfolds in four carefully orchestrated steps:
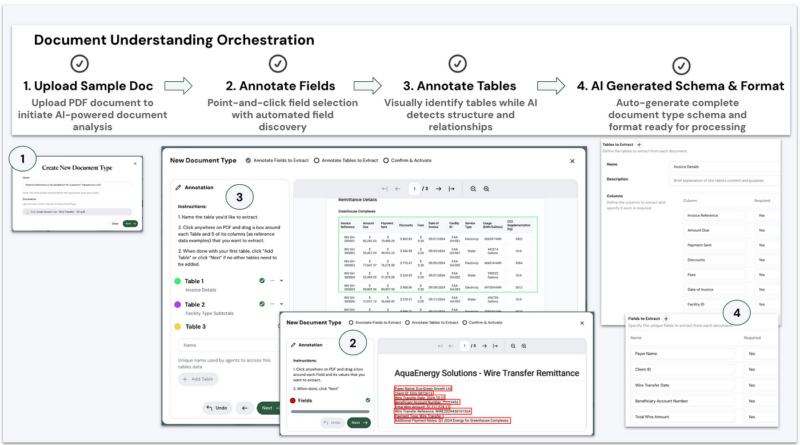
1. Smart document analysis & upload
Rather than beginning with technical configurations, business analysts start with what they know best — the documents themselves. The DUA’s intelligent analysis immediately begins mapping document structures to business concepts, laying the foundation for natural language data engineering.
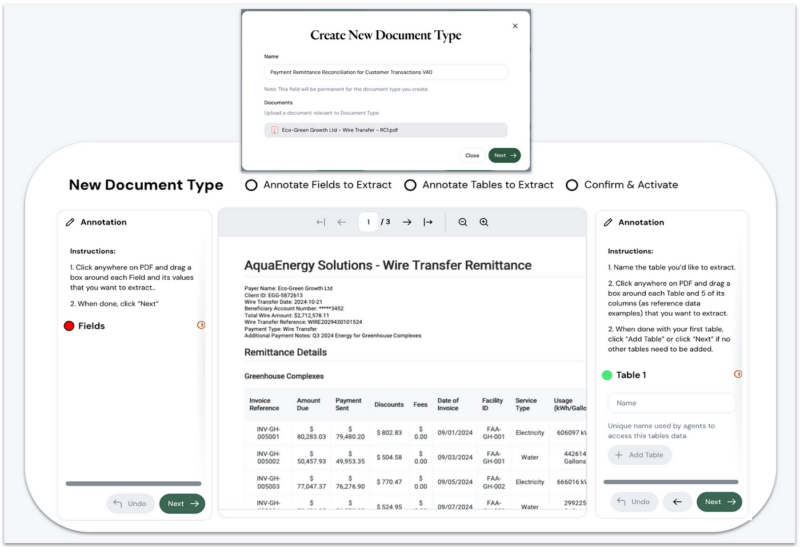
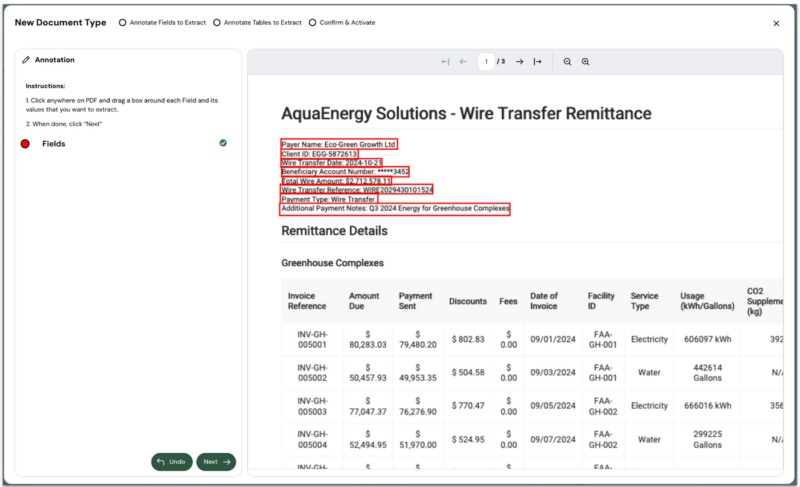
2. Visual field schema definition
The DUA enables business analysts to define core document fields through simple visual selection. As users click on key information fields like Customer ID or Payment Reference Number on the first and last pages, the system suggests appropriate field names and data types based on content analysis.
This visual interface represents a fundamental shift from technical field mapping to business-driven data modeling. Analysts define their data needs through intuitive interaction rather than complex configuration files.
3. Table structure recognition
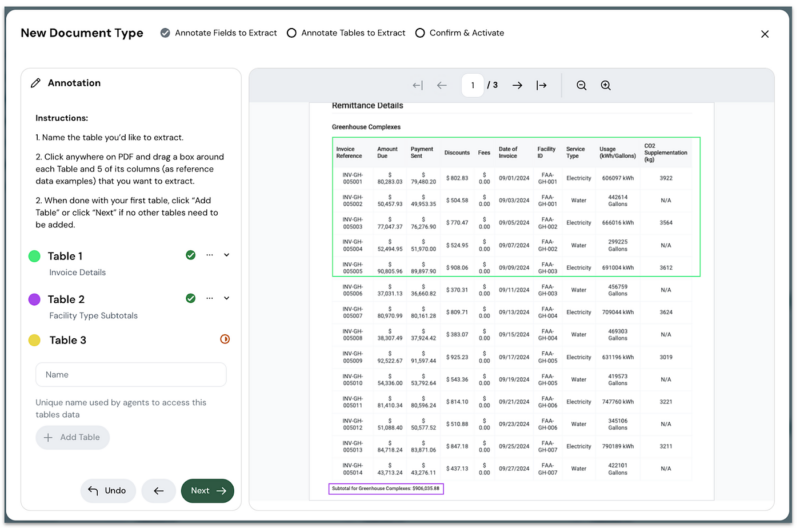
Instead of writing complex table parsing logic, business analysts identify the tables that matter for their analysis. The DUA handles the technical complexity of maintaining relationships and structure across pages. When analysts select a table region, the system automatically:
- Detects column headers and their relationships
- Identifies repeating patterns across pages
- Maps hierarchical connections between line items and subtotals
- Preserves facility type context from table headers
4. AI-powered schema & format generation
When business analysts complete their document annotations, the DUA’s sophisticated AI engine performs two critical tasks.
First, it generates a comprehensive Document Type schema that defines the standardized structure for remittance processing:
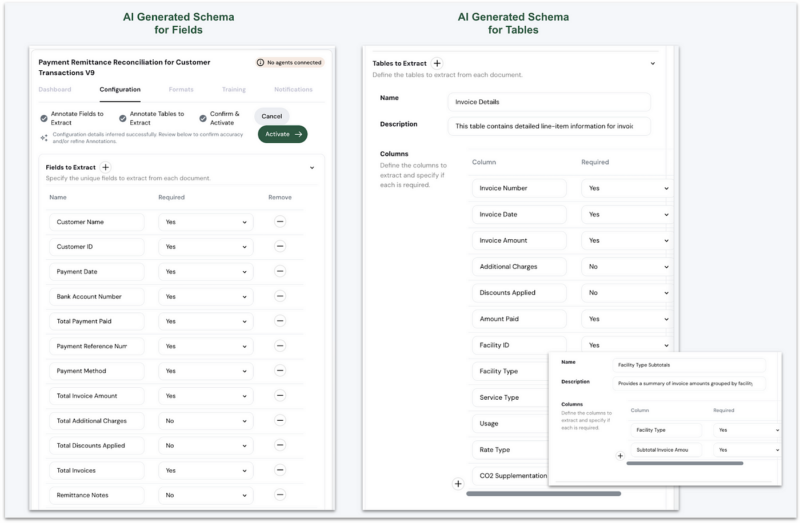
The schema captures all essential elements, including required fields, table structures, and validation rules — establishing a consistent processing framework regardless of source format.
Second, the DUA automatically creates a complete Document Format configuration that maps this source document to the standardized schema:
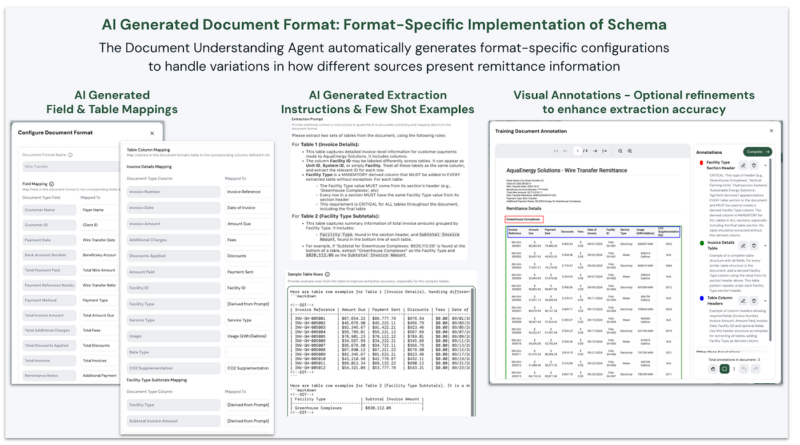
This format configuration includes:
- Field and table mappings that align source terminology with standard definitions
- Optimized extraction instructions with examples from the document
- Visual annotations that enhance extraction accuracy
The result is more than just a technical schema — it’s a complete data engineering pipeline expressed in business terms. The generated format includes sophisticated data transformations that traditionally require extensive coding, all configured through natural language and visual annotations.
Data engineering for business analysts: the power of natural language & virtual data
Traditional document automation requires data engineers to write complex code for data transformation — extracting scattered information, maintaining relationships, and creating unified views for analysis. The Document Understanding Agent revolutionizes this approach by enabling business analysts to perform sophisticated data engineering tasks using natural language, virtual structures, and intuitive annotations.
How?
One of DUA’s more advanced features is its ability to create logical data structures that don’t physically exist in the document. We call these virtual or derived columns and tables. In the payment remittance example, let’s see where we use these constructs:
- Virtual Columns — The system automatically adds a “Facility Type” column to the invoice details table, deriving values from each table’s header section (Greenhouse Complexes, Vertical Farming Units, etc.). This enables robust categorization and analysis capabilities.
- Virtual Tables — The DUA creates a “Facility Subtotals” summary table that aggregates subtotal information from all pages into a unified view with facility type and amount columns. This transforms scattered subtotal entries into structured, analyzable data.
Check out the video below, where the DUA agent outputs sample rows from the invoice table with the virtual columns and the virtual Facility Type Subtotals table.
Watch the DUA transform a 100-page document into clean, analysis-ready data structures through virtual columns and tables
In this demonstration, notice how the DUA transforms a complex 100-page document into clean, analysis-ready data structures — all configured through natural language instructions. What traditionally required SQL transformations, custom ETL code, and technical expertise is now expressed in business terms:

These simple instructions trigger powerful data engineering outcomes:
- Virtual columns automatically categorize transactions by their business context
- Virtual tables aggregate scattered information into unified analytical views
- Hierarchical relationships are maintained without complex join operations
Business analysts can further refine these transformations through intuitive visual annotations, marking key elements like section headers and subtotal entries. The DUA learns from these annotations, adapting to document variations while maintaining consistent data structures.
Check out the additional context the business analyst can add for the annotation named “Facility Type Section Header.”
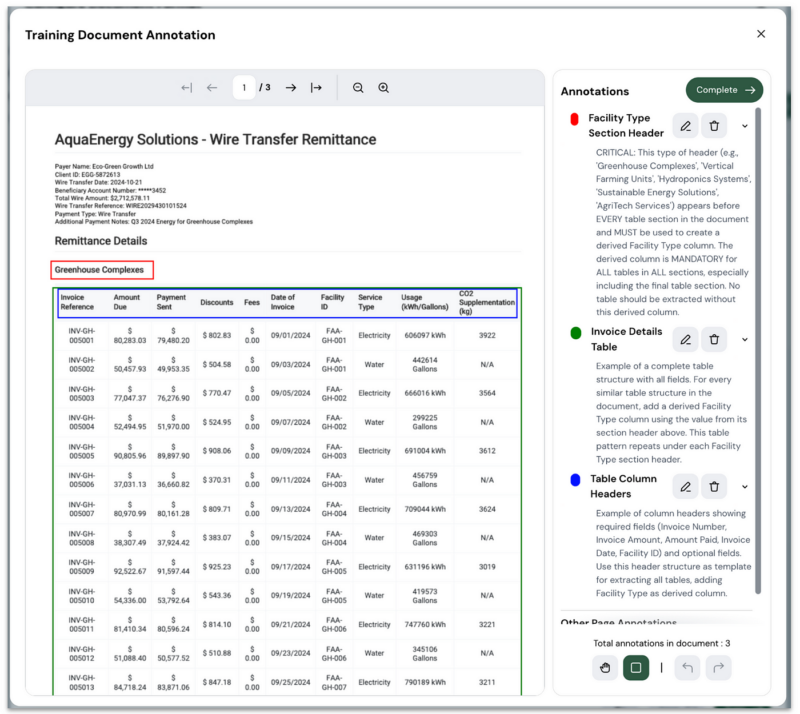
What makes this approach revolutionary is how it puts sophisticated data engineering capabilities in the hands of business users who understand the data best. Through natural language instructions and visual guidance, analysts can:
- Define complex data transformations without writing code
- Create unified views from scattered information
- Maintain critical business relationships in the data
- Ensure consistency across document variations
This represents a fundamental shift in document automation — from technical implementation to business-driven data engineering. Business analysts can focus on defining the data structures they need for analysis, while the DUA handles the complex transformation logic automatically.
Continuous learning & validation
Unlike traditional data engineering, where changes require code updates, the DUA’s continuous learning enables business analysts to refine their data transformations through natural feedback and examples. Each annotation and correction improves the system’s understanding, creating an iterative cycle of improvement driven by business expertise rather than technical modifications.
DUA uses the following techniques to accomplish this:
- Multi-Shot Learning: The system refines its understanding through multiple examples, identifying patterns and variations.
- Format Validation: Automated testing ensures extraction accuracy meets business requirements.
- Feedback Integration: The system incorporates user feedback to improve mapping accuracy and handling of edge cases.
This combination of intuitive interaction and continuous learning enables business users to rapidly configure complex document processing while maintaining high accuracy and adaptability to new variations.
The result is a dramatic acceleration in time-to-value for document automation initiatives. What previously required weeks of technical configuration can now be accomplished in hours by business users who understand their documents best.
Looking ahead: the future of intelligent document processing
Document Intelligence 1.1 represents more than a technological advancement — it fundamentally transforms who can drive document automation in the enterprise. By combining specialized AI agents with natural language data engineering capabilities, we’re enabling a new paradigm where:
- Business analysts can perform sophisticated data transformations without coding expertise
- Complex document structures can be modeled through intuitive visual tools rather than technical configurations
- Data relationships and hierarchies can be maintained through natural language instructions instead of complex ETL pipelines
- Continuous learning happens through business feedback rather than code updates
This democratization of data engineering capabilities is especially powerful because it puts control in the hands of those who understand the business context best. Instead of coordinating between technical teams and business users, organizations can now empower their analysts to:
- Define virtual data structures that match their analytical needs
- Create unified views from scattered document information
- Maintain critical business relationships across document variations
- Ensure data consistency through intuitive validation rules
The future of intelligent document processing isn’t just about finding information or basic automation — it’s about enabling business experts to engineer sophisticated data pipelines through natural language and visual tools, while AI agents handle the technical complexity of execution. This combination of business-driven configuration and autonomous processing creates a new standard for enterprise document automation.
Ready to experience the power of natural language data engineering?
- Sign up for our RAD Program
- Learn more on our DI Product Page
- Explore detailed capabilities in our DI documentation